Our goal at this point is to understand enough about run-time
organization to understand the information the compiler must collect
while processing declarations.
The key idea is that at run-time all memory will be allocated in blocks.
There will be frames (i.e. activation records) for method invocations
and objects allocated on the heap in response to the construction
of new objects and arrays.
Ultimately, our understanding of run-time storage management will
have to include knowledge of how to generate code to determine
the address of any block of storage that contains a variable
we want to access.
That is, we will have to figure out where we can find
pointers to the current method's frame, the current
object, and objects corresponding to all the scopes (i.e.
classes) that textually surround the code of the
executing method.
For now, however, we will just assume we can find the necessary
pointers to blocks of memory and think about the organization
within the blocks to make sure that we collect enough information
while processing declarations to determine the offset to each
variable/method within the blocks of memory we allocate.
As a start, we can identify four types of structures that will
be allocated for Woolite programs. (Good news, these will
also be sufficient for many other languages).
Method Activation Records
Each time a method is invoked, we will push a block of
storage to hold the method's parameters and local variables
onto a stack. This block of memory will also hold things
like the return program counter and saved values of some
critical pointers (like the pointer to the caller's frame and
the previously active object).
Object Records
Each time a program constructs an object (not an array),
we will allocate space on the heap to hold all of the
instance variables declared in the object's class (including
inherited variables -- even though we can't access them).
Dispatch tables
When a method is invoked, we need a way to determine
how to interpret the name of the method given the actual
type of the object involved. To make this possible, each
object structure allocated on the heap will contain a pointer
to a table of pointers to the code for the method's associated
with the type of the object.
These don't need to be dynamically allocated. There will
be one per class and they can be statically allocated
before execution begins.
Arrays
We will also need to allocate blocks of storage
to hold the elements of arrays created by constructions.
We distinguish these from the allocation of single objects
because they won't need to contain dispatch tables.
For variables (i.e. instance variables, local variables, and formal parameters)
stored within activation records and objects, the semantic processor's
task it to determine the offset to each variable within the block of memory
allocated.
Variables are often allocated in order within the block to which they
belong as their declarations are processed.
To know each variable's offset, all the compiler has to do is keep
track of the total amount of space used by all of the previously
processed variables.
In general, this will involve being able to determine the amount
of memory required for each variable, i.e. required for the type
associated with each variable.
In Java-like OO languages, this is made somewhat easy by the
fact that all values of non-primitive types are represented by
pointers to their own block of memory on the heap and therefore
all variables of all such types require the same amount of space,
the space required to store a pointer.
In Woolite and on the 34000, there is only one primitive type, int,
and it takes the same amount of space as a pointer, 1 word.
Therefore, all variables take one word, and the compiler
does not have to do any work to determine the type of a variable.
The amount of space consumed by n variables is just n.
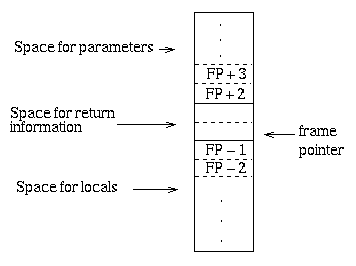
The actual layout of activation records for methods is strongly influenced by
the hardware support for function/method calls on the target system.
Most machine architectures have special instructions to
support calling procedures and allocating memory for their
variables. These instructions require the code to follow the
architecture's conventions about where variables are
located relative to the register that points to the activation
record.
To get a feel for the impact of a machine architecture on
variable allocations, recall the stack frame layout
conventions of the MC68000/WC34000:
A compiler for such a machine needs to keep track of offsets for
local variables and parameters separately since they "grow" in
different directions.
For Woolite, it is sufficient to simply count the number of parameters
and local variables. It is then easy to compute the offset to the nth
variable or nth parameter.
The layout of blocks of memory on the heap is slightly complicated by
the ability to extend classes.
Although Woolite does not allow code within the methods of a subclass
to access the variables declared in a superclass, if a method associated
with the superclass is invoked on an object of the subclass, the
method can reference the superclass variables, so each object
of a given class must include space for all variables declared in
all superclasses.
If class P is a superclass of B and P declares a variable x, then the
offset to x must be the same in P objects as in B objects, because
the code we generate for methods declared in P will use P's
offset to x when x is referenced even if such a method is invoked on
an object of class B.
This simply means that when we start counting the number of variables
in a subclass, the count should start out equal to the total number
of variables declared in all superclasses.
In an OO language the supports inheritance, we cannot in general implement method
invocations by branching directly to the code for the correct method. Instead, we must
build tables of pointers to the code for each classes methods and dynamically select the
correct methods to invoke at run-time.
Again, assume the P is a superclass of B and that P defines a method, m, which is
overridden by B.
If the program includes a variable, o, of type P, then we can assign o to refer to either
an object of type P or B (or any other subclass of P).
As a result, when processing the invocation
o.m( ... )
we cannot tell at compile time which version of m should be executed.
The method executed will depend on the class of the object assigned to o when the invocation is executed, but not the precise object. Therefore we can solve
this problem by building a table containing pointers to the method code to use for
each method of each class. We will call this a dispatch table.
To make this work, we have to be able to put the pointer to the code for a method
like m at the same offset in the table of pointers for each subclass of P (including
those that override m).
Therefore, as with variables, we will basically assign offsets to methods by counting
the total number of methods declared in a class and its superclasses, but only
counting methods that do not override inherited methods. Instead, each
method that overrides another will be assigned the same displacement
as the method it overrides.
In addition to building these tables, we have to be able to find the correct table
quickly when executing an invocation like
o.m( ... )
As a result, each object allocated on the heap will have to include a pointer to
the dispatch method for its class.
Arrays don't require dispatch table pointers. Each array will be a collection of integers
(which require no dispatch tables) or pointer to objects that each contain their own
dispatch table pointers.