| How Lex Works |
 +. Any such expression
can be rewritten as (*). Accordingly, if we figure out how
to handle concatenation and *, we don't have to worry about +. We can just rewrite
any expression that uses + before we start trying to build an FSA.
+. Any such expression
can be rewritten as (*). Accordingly, if we figure out how
to handle concatenation and *, we don't have to worry about +. We can just rewrite
any expression that uses + before we start trying to build an FSA.
 .
.
 .
.
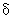 : x -> .
called the set of final
states.
0 of called the initial state.
would have
been undefined we will define its result to be the error state.
to strings over the input
alphabet. In particular, we can define
: x -> .
called the set of final
states.
0 of called the initial state.
would have
been undefined we will define its result to be the error state.
to strings over the input
alphabet. In particular, we can define
 : x * -> recursively as
( ,
: x * -> recursively as
( ,  ) =
( ,
) =
( ,  x ) = ( ( , ), x )
x ) = ( ( , ), x )
{
( 0, x ) = 1.
 (i.e. concatenation)
is a bit trickier.
and independently.
may have many final states.
.
is a* and is aaab*.
-transitions.
with
-transitions to the initial state in the machine for .
.
.
: x (+ )
-> 2.
called the set of final
states.
0 of called the initial state.
to a function
that handles transitions on strings rather than single symbols from .
for an FSA, the for a NFSA must accept a set
of states and a string as its input:
(i.e. concatenation)
is a bit trickier.
and independently.
may have many final states.
.
is a* and is aaab*.
-transitions.
with
-transitions to the initial state in the machine for .
.
.
: x (+ )
-> 2.
called the set of final
states.
0 of called the initial state.
to a function
that handles transitions on strings rather than single symbols from .
for an FSA, the for a NFSA must accept a set
of states and a string as its input:
is to take care of the productions
by defining the closure of a set of states:
We define the closure of a set of states, closure(P) to be the smallest set P' such that:
 P.
i P' and j ( i,
) then j P'.
( P, ) = closure( P )
( P, x ) = closure( ( ( P, ), x ) ).
to the initial
state of the machine and the input produce a set of states that includes at least one
of the machine's final states.
*.
.
's machine
to this new initial state.
P.
i P' and j ( i,
) then j P'.
( P, ) = closure( P )
( P, x ) = closure( ( ( P, ), x ) ).
to the initial
state of the machine and the input produce a set of states that includes at least one
of the machine's final states.
*.
.
's machine
to this new initial state.
| How Lex Works |