|
|
CS 334
|
Here we will examine parsing using XML as our example. XML is a "hot" topic these days. XML stands for extensible markup language. HTML for making web pages is an example of a standard generalized mark-up language (SGML), while XML can be seen as being more general than HTML, but not as rich as SGL. The key difference between XML and HTML is that XML is a meta-language (the tags are not fixed - either in syntax or semantics) that is designed so that richly structured documents could be sent over the web, whether or not those documents were designed to be displayed. Thus an XML document might be used to transfer information across the internet from one computer to another in such a way that a program on one computer could generate the data, while the other could read it and operate on it.
The hope is that standards will be created for different kinds of information to be transmitted. Then anyone wishing to transfer that kind of information will use the same format.
For the most part, the XML we will use here will be very similar to HTML that you have likely run into. We will use only simplified XML in that we will not allow tags to carry attribute information.
An example of attribute information is contained in the "body" tag of this html document. The 3rd line of this document reads:
<body bgcolor="#eeffff">The attribute "bgcolor" is used to set the background color of this document when displayed on web pages.
To make our life simpler, we will just allow tags without attributes. Thus we will only allow <body>. My parser is also pretty stupid in that it will only allow exact matches of tags. Extra spaces will screw things up, so an exact match is necessary. My lexical scanner does convert all tags to all upper case, so there is that flexibility. We will call the language described here SXML (for simplified XML).
The syntax for SXML is
SXML -> (OpenTag t) contents (CloseTag t)
contents -> (Plain s) contents |
tagged contents |
ε
tagged -> (OpenTag t) contents (CloseTag t)
where s and t stand for strings.
The contents non-terminal has 3 productions. The first generates a Plain token and then more contents. The second generates a tagged non-terminal and then more contents. The last option in the definition of contents is "epsilon", which indicates that contents may be replaced by an empty string. The basic idea is that from contents, one can derive a sequence of either plain text or tagged items. The tagged non-terminal generates an OpenTag token, more contents, and a matching closeTag token.
I must admit to cheating a bit here. The grammar above is not officially a context-free grammar if the tags are required to match. I'm going to ignore that for now and simply claim that I could make it context-free if I had a list of all possible tags. We'll ignore this, however, for simplicity.
Here is a series of productions from SXML:
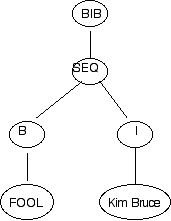
SXML => (OpenTag BIB) contents (CloseTag BIB)
=> (OpenTag BIB) tagged contents (CloseTag BIB)
=> (OpenTag BIB) tagged tagged contents (CloseTag BIB)
=> (OpenTag BIB) tagged tagged (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) contents (CloseTag B) tagged (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) (Plain FOOL) contents (CloseTag B) tagged (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) (Plain FOOL) (CloseTag B) tagged (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) (Plain FOOL) (CloseTag B) (OpenTag I) contents (CloseTag I) (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) (Plain FOOL) (CloseTag B) (OpenTag I) (Plain Kim Bruce) contents (CloseTag I) (CloseTag BIB)
=> (OpenTag BIB) (OpenTag B) (Plain FOOL) (CloseTag B) (OpenTag I) (Plain Kim Bruce) (CloseTag I) (CloseTag BIB)
The string of tokens on the last line is the final result.
We can use the recursive structure of the context free grammar to create a "recursive descent compiler". The code for the whole lexical scanner and parser is available. Here we will only focus on the parser.
The data type of elements generated by the lexical scanner is
datatype token = Plain of string | OpenTag of string | CloseTag of string;The lexical scanner reads in a string or text of XML and returns a list of items of type token. Here is the example of a translation. The string:
"<BIB><B>FOOL</B><I>Kim Bruce</I></bib>";is transformed by the lexical scanner into:
[OpenTag "BIB",OpenTag "B",Plain "FOOL",CloseTag "B",OpenTag "I",
Plain "Kim Bruce",CloseTag "I",CloseTag "BIB"]
The parser transforms the list of tokens into an element of type term:
datatype term = AST_TAG of string * term | AST_TEXT of string |
AST_SEQ of term*term | AST_EMPTY | AST_ERROR of term*string;
The list of tokens above is transformed by the parser into:
AST_TAG
("BIB",
AST_SEQ
(AST_TAG ("B",AST_TEXT "FOOL"),AST_TAG ("I",AST_TEXT "Kim Bruce")))
We can understand this parsed XML text as a tree by labelling nodes with
their tags:
Let's now see how we can take the grammar and write a parser to build trees of this form (i.e., elements of type term. The function parse takes a list of tokens and returns an element of type term. If the list of tokens does not represent a legal term, then it returns a term of the form AST_ERROR (term,message). The function parseContents takes a list of tokens, and returns an element of type term
The actual function will follow the grammar production for SXML very closely. Thus we can recognize a list representing a term generated by SXML by starting off by finding an open tag, then contents, then a close tag. Recognizing a list of tokens representing contents is more complex as it may be a list starting with plain text, starting with an open tag, or it may be just an empty list. How do we know which to look at?
In order to write a "predictive" parser we need to be able to look at the beginning of the list of tokens (hopefully only the first element in the list) and decide which of the alternatives is to be taken. This can be done if we can decide in advance what some extra information about the productions. This information is provided by two functions, First and Follow, both of which operate on non-terminals in the grammar. If X is a non-terminal, then First(X) is a set of all tokens that may occur at the beginning of a string generated from X. Follow(X) is the set of all tokens that may occur immediately after a string generated from X. Let's see how we can calculate these (by hand, rather than in a computer language).
Because there is only one production for XML, it is clear that First(XML) = {(OpenTag s)}. Let's now jump to tagged before proceeding to the harder contents. Non-terminal tagged has only one production, so First(tagged) = {(OpenTag t)}.
The case for contents is not as clear. The first production starts with (Plain s), which is no problem. However the second starts with non-terminal tagged. Thus First(contents) includes First(tagged), as a result of the second production. The third production generates an empty string. There is no first token with an empty string! So how do we know when to take that production? It would be sufficient to know the next tokens that could ever occur immediately after a string generated by contents. This is why we also calculate Follow!
Because XML is the start symbol and does not occur on the right side of any productions, we let Follow(XML) = {eof}. The token eof is used to indicate that there may be nothing left to parse after seeing XML. On the other hand the non-terminal contents appears in the first production just before (CloseTag s). It also appears as the last token on the right side of two productions from contents, but those clearly don't give us any new following symbols (this would not be the case if it was a production from anything but the same non-terminal! -- see the text for details). Thus Follow(contents) = {(CloseTag t)}. Because the last production from contents goes to the empty string, this means that the next token after generating the empty string can be anything in Follow(contents). Hence the production going to the empty string gives a possible first token of the element in Follow(contents), namely (CloseTag t). Finally to calculate Follow(tagged) we see that tagged only occurs on the right side of a production in the second production of contents, and is followed immediately by contents. Thus Follow(tagged) = First(contents).
In summary,
First(SXML) = {(OpenTag t)}
First(contents) = {(Plain s), (OpenTag t), (CloseTag t)}
First(tagged) = {(OpenTag t)}
Follow(SXML) = {eof}
Follow(contents) = {(CloseTag t)}
Follow(tagged) = First(contents) = {(Plain s), (OpenTag t), (CloseTag t)}
Now if we look at the three elements of First(contents) then we
notice that the first of these is only associated with the first production
from contents, the second with only the second production, and the
third with only the third production. The key here is that there is no
overlap in the tokens from First(contents) associated with the
three productions. Thus, whichever token appears will tell us exactly
which production of contents to use. Because this is determined
exactly, we can write a "predictive parser".
Here is the code for the parser and supporting functions:
(* Output an error message *)
fun error (msg:string) = print msg
(* Combine oldTree and newTree into a combined tree.
If oldTree is AST_EMPTY then ignore it, otherwise combine using
AST_SEQ.
combineTrees = fn : term -> term -> term *)
fun combineTrees oldTree newTree =
if oldTree = AST_EMPTY then
newTree
else
AST_SEQ(oldTree,newTree)
(* Parses contents. If an expression is found, returns a
tuple containing the ast for the expression and the input
following the expression. If an expression is not found, it
returns an error and consumes all remaining input.
*)
(* contents -> (Plain s) contents | tagged contents | ε *)
fun parseContents (tree,(Plain s)::others) = (* #1: plain text *)
parseContents( addSeq tree (AST_TEXT s) others )
| parseContents (tree,(OpenTag tag)::others) = (* #2: start tag *)
parseContents( parseTagged(tree,(OpenTag tag)::others) )
| parseContents (tree,(CloseTag tag)::others) = (* #3: end of contents *)
(tree, (CloseTag tag)::others)
| parseContents (tree,[]) = (tree,[])
(* parses a tagged element in XML *)
(* tagged -> (OpenTag t) contents (CloseTag t) *)
and parseTagged(tree,(OpenTag tag)::others) = let
val (subtree,rest) = parseContents(AST_EMPTY,others)
in
if (hd rest) = (CloseTag tag) then
addSeq tree (AST_TAG(tag,subtree)) (tl rest)
else
(error "matching closing tag not found\n";
(AST_ERROR (tree,"matching closing tag not found"), nil))
end
| parseTagged(tree,_) = (error "programming error in parseTagged\n";
(AST_ERROR (tree,"programming error in parseTagged"), nil))
(* Return an AST for the list of tokens passed in. *)
(* SXML -> (OpenTag t) contents (CloseTag t) *)
fun parse ((OpenTag tag)::tokens) =
let
val (ast1, others) = parseContents (AST_EMPTY, tokens);
in
if (hd others) = (CloseTag tag) andalso (length others = 1) then
AST_TAG (tag,ast1)
else
(error "Fatal error -- more input than expected.\n";
AST_ERROR (ast1,"More input than expected."))
end
| parse _ = (error "Fatal error -- file does not start with tag.\n";
AST_ERROR (AST_EMPTY,"File does not start with tag."))
Let's look at parse first. After removing the OpenTag token, it tries to recognize contents. That returns a tree and any remaining tokens not used up by looking for contents. If all that is left is the one corresponding CloseTag token to the original OpenTag, then all is well, and the tagged tree is returned. Otherwise an error is reported.
Now let's take a look at parseContents. It takes a term (called tree) and a list of tokens. Originally it is provided with an empty term (AST_EMPTY, but normally it will hold the term recognized to this point.
If the next token is a Plain token then the first production must be used. Thus it builds a term using AST_TEXT and then uses AST_SEQ to sequence it after the previous term (if the previous term was AST_EMPTY then that term is ignored -- that is what function addSeq does).
If the next token is an OpenTag token, then this corresponds to the second production and we attempt to recognize tagged.
If the next token is a CloseTag token, then this corresponds to the last production, and we are finished with recognizing contents, so we simply return the term and the rest of the tokens remaining.
Finally, parseTagged is relatively straightforward. If the first token is an OpenTag token then it is removed and the system looks for a string generated from contents, followed by the appropriate matching CloseTag. If that sequence is not recognized then an error is reported.
Please read the material in section 4.6 of the text. I hope that the combination of that material and what we have covered in class will give you a pretty good understanding of predictive recursive descent parsing. While there are other methods of parsing available (including some that use tools like yacc and lex), this technique will work with most languages, though you may have to rewrite the grammars as suggested in the text.
Meaning of a program (once know it is syntactically correct).
Work with virtual (or abstract) machine when discuss semantics of programming language constructs.
Run program by loading it into memory and initializing ip to beginning of program
Official language definitions: Standardize syntax and semantics - promote portability.
Often better to standardize after experience. -- Ada standardized before a real implementation.
Common Lisp, Scheme, ML now standardized, Fortran '9x.
Good formal description of syntax, semantics still hard.
Backus, in Algol 60 Report promised formal semantics.
Semantics given in style of "natural semantics". Kind of operational semantics.
"e = v" means that when "e" is evaluated, it should return the value "v".
E.g. First few rules say nothing to do with simple values and function names:
Therefore if encounter simple value or function name, just return it - no further evaluation is possible. Think of these as base cases for the interpreter.
More interesting rules say that in order to evaluate a complex expression, first evaluate particular parts and then use those partial results to get the final value.
Look at following rule:
b => true e1 => v (5) --------------------------- if b then e1 else e2 => v
We read the rule from the bottom up: if the expression is an if-then-else with components b, e1, and e2, and b evaluates to true and e1 returns v, then the entire expression returns v. Of course, we also have the symmetric rule
b => false e2 => v (6) ---------------------------- if b then e1 else e2 => v
Thus if we wish to evaluate an expression of the form "if b then e1 else e2" then first evaluate "b". If b evaluates to true, then, using rule (5), evaluate e1 to get some value, v. Return the value, v, as the final value of the "if" expression. If b evaluates to false, then use rule (6) and return the value of e2.
The application rules in homework 3 are similar. Essentially, evaluate the function. If it evaluates to one of the primitive functions, evaluate the argument and return the result of applying the primitive function to the value of the argument. Thus, the actual rule to be used is determined by the value of the function.
The following is an example which shows why you must evaluate the function part as well as the argument:
(if false then succ else pred) (pred 7)
The function evaluates to pred and the argument evaluates to 6. Using rule (8) from the homework, this should evaluate to 5.
Variable has 6 components

Scope and Lifetime same in some languages - clearly different in some (FORTRAN)
N := N + 1First N refers to location (l-value), second to value (r-value).
Obtaining value of variable called dereferencing. (going from reference or location to value)
E.g., name can change (via call by reference parameter)
Aliasing:
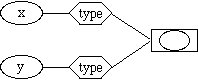
Similarly assignment of variables (e.g., x := y) can be by copying or by sharing.
In copy semantics, target variable retains its location, but copies new value from source variable.
In sharing semantics, target variable gets location of source variable, so both share the same location (like objects in Java).
Constants have values, but no location.
One way of classifying a language is according to sorts of entities that can be bound to an identifier. Called denotable values.
In Pascal, objects which can be bound to id's and corresponding declarations are:
Static vs Dynamic
Scope is associated with the static text of program.
Can determine scope by looking at structure of program rather than execution path telling how got there.
May have holes in scope of variable
program ...
var M : integer;
....
procedure A ...
var M : array [1..10] of real;
begin
...
end;
begin
...
end.
Variable M declared in main program is not visible in procedure A, since
new declaration of M "shades" old declaration.
Symbol table keeps track of which declarations are currently visible.
Think of symbol table as stack. When enter a new scope, new declarations are pushed on and can shade old ones. When exit scope, declarations arising from the scope are popped off.
Back to:
kim@cs.williams.edu