| |
CS 334
|
Distributed in Tuesday class after break. Due on Friday at 2:30pm.
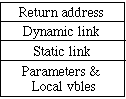
Activation record pushed onto stack each time there is a procedure call.
Popped off after return.
Ex.
Program main;
type array_type = array [1..10] of real;
var a : integer;
b : array_type;
Procedure x (var c : integer; d : array_type);
var e : array_type;
procedure y (f : array_type);
var g : integer;
begin
:
z(a+c);
:
end; {y}
begin {x}
: ..... := b[6].......
y(e);
:
end; {x}
Procedure z (h : integer);
var a : array_type;
begin
:
x (h,a);
:
end;
begin {main}
:
x (a,b);
:
end. {main}
Draw static scopes.
Dynamic calling sequences:
Main => x => y => z => x => y ....Look at picture of run-time stack after x calls y 2nd time.
How do we get reference to b in x? to a in y? Where can these variables be held?
Dynamic link (called control link in text) provides pointer to beginning (usually) of caller's activation record.
Static link provides pointer to beginning of activation record of statically containing program unit.
How do find location of variable? Easy in FORTRAN! Not here!
Must keep track of the static nesting level of each variable and procedure.
When access vble or procedure, subtract static nesting level of definition from static nesting level of the definition.
Tells how far down static chain to environment of definition.
Example:
Name Level Name Level
main 0 y 2
a 1 f 3
b 1 g 3
x 1 z 1
c 2 h 2
d 2 a 2
e 2
Notes:
Sol'n: Piece of cake - each activation record for a given procedure is identical in size and location of info. Pascal.
E.g. x : Array [m..n] of integer;
often called semi-dynamic
Sol'n: Space for vble descriptors allocated at fixed offset.
Location of local vbles and parameters may have to be calculated from this info at each invocation (e.g., store starting location on stack and use indirection).
Sol'n: Separate data area called heap is required.
Lifetime of data independent of lifetime of calling unit.
Allocates and deallocates new space when necessary.
Complicated as size of blocks needed varies.
Requires careful handling to preserve space.
Stack and heap space do not overlap during execution.
Notice difference btn static, stack-based, and dynamic memory allocation is binding time!
Since type can change dynamically, so can size and contents of descriptor (e.g. # dim's and bounds).
Activation record contains ptr to descriptor which contains ptr to vble.
All accesses provide for run-time check on type - slow.
Name of vble must be stored in activation record (w/ ptr to descriptor).
Example:
program A var B:integer procedure C; begin ..... B .... end; procedure D(B:integer); begin C; end; begin D(12); end.Trace stack during execution.
Costs: More space, slower access.
Gains: Flexibility.
Possible to implement by keeping table of loc'ns of active variables.
Overhead when entering and leaving procedures.
We cannot use a stack-based discipline for function calls in a functional language because of difficulties in returning functions as values from other functions.
As a result, activation records must be allocated from a heap. Similar difficulties in passing around closures result in most object-oriented languages relying on heap allocated memory for objects. Because it is often not clear when memory can be safely freed, such languages usually rely on an automatic mechanism for recycling memory.
In this lecture we discuss methods for automatically managing and reclaiming free space. We being with the simpler task of managing free space.
When a request is made (e.g., via a "new" statement) for a block of memory, some strategy will be undertaken to allocate a block of memory of the desired size. For instance one might search on the list of free space for the first block which is at least as large as the block desired or one might look for a "best fit" in the sense of finding a block which is as small as possible, yet large enough to satisfy the need.
Whichever technique is chosen, only enough memory as is needed will be allocated, with the remainder of the block returned to the stack of available space.
Unless action is taken, the heap will eventually be composed of smaller and smaller blocks of memory. In order to prevent this, the operating system will normally attempt to merge or coalesce adjacent blocks of free memory. Thus whenever a block of memory is ready to be returned to the heap, the adjacent memory locations are examined to determine whether they are already on the heap of available space. If either (or both) are, then they are merged with the new block and put in the heap.
Even with coalescing, the heap can still become fragmented, with lots of small blocks of memory being used alternating with small blocks in the heap of available space.
This can be fixed by occasionally compacting memory by moving all blocks in use to one end of memory and then coalescing all the remaining space into one large block. This can be very complex since pointers in all data structures in use must be updated. (The Macintosh requires the use of handles in order to accomplish this!)
Aside from the manual reclamation of storage using operations like "dispose", there are two principle automatic mechanisms for reclaiming storage: reference counting and garbage collection. The first is an eager mechanism while the second is lazy.
Thus an assignment of pointers of the form p := q is executed then the block of memory that p originally points to has its reference count decreased by one, while that pointed to by q would have its count increased by one.
If the count on a block of memory is reduced to zero, it should be returned to the heap of available space. However, if it has pointers to other blocks of memory, those blocks should also have their reference counts reduced accordingly.
One drawback of this system is that each block of memory allocated must have sufficient space available to maintain its reference count. However a more serious problem is the existence of circular lists. Even if nothing else points to the circular list, each item of the list will have another item of the list pointing to it. Thus even if a circular list is inaccessible from the program, the reference counts of all of its will still be positive and it will not be reclaimed.
The mark and sweep algorithm for garbage collection starts with all objects accessible from the current environment (or symbol table), marks them and then does the same with all objects accessible from those, etc. After this phase the algorithm sweeps through all of memory, collecting those blocks which were not marked in the first phase (and unmarking the rest). Normal processing then resumes.
There are two problems with this technique. The first is the space necessary in order to hold the mark (though this can just be one bit). A more serious problem is that this algorithm requires two passes through memory: The first to mark and the second to collect. This can often take a significant amount of time (notice the delays in emacs, for example), making this sort of garbage collection unsuitable for real-time systems. This disadvantage has led to this method being abandoned by most practical systems (though still described in texts).
There have been several recent improvements in garbage collection algorithms. The first is sometimes known as a copying collector.
In this algorithm the memory is first divided into two halves, the working half and the free half. When memory is exhausted in the working half, live nodes are copied to free half of memory, and the roles of the two halves can be switched. Notice that the collector only looks at live cells, rather than all. Can be done incrementally, so that very little cost is paid at any one time (less than 50 instructions, probably). This tends to work well with a virtual memory system.
Another strategy is to use a generational collector in which only bother to garbage collect recently allocated blocks of memory. Older blocks are moved into stable storage and not collected as often. Studies have shown that most reclaimed garbage comes from more recently allocated blocks of memory.
In highly parallel architectures can have garbage collection take place in background, minimizing or eliminating delays.
When pass function (or procedure) parameters in stack-based languages, must also pass the equivalent of a closure. In particular must pass the environment in which the function was defined. This is accomplished by passing the appropriate static pointer with the function so that can find non-local variables. Usually pass the pair (ep,ip) of environment pointer and instruction pointer as the "closure" of a procedure, when it is passed as a parameter.
Returning functions from functions is harder since defining environment may go away:
program ret;
function a(): function (integer): integer;
var m: integer;
function addm (n: integer): integer;
begin
return (n + m)
end;
begin (* a *)
m := 5;
return addm
end; (* a *)
procedure b (g: function(integer): integer);
begin (* b *)
writeln(g(2))
end (* b *)
begin (* main *)
b(a()) (* note that a() returns a function, which is
then passed to b *)
end.
When b(a()) is called, a() returns a function which depends on the non-local
variable m, but m has gone away by the time the function is actually applied.
Hence languages (like ML) which allow functions to return functions cannot
use the simple stack discipline - must keep around activation records even
after their associated function or procedure has returned.
Definitional have constant, variable, procedural, and functional.
Constant parameters are treated as values, not variables - different from
call-by-value.
Default for Ada in parameters.
Can think of call-by-name as definitional with expression parameter.
Note that difference in parameter passing depends on what is bound (value or address) and when it is bound.
Another way of classifying parameters is to note that each parameter mechanism corresponds to declaration in language:
E.g., constant, variable (def. & declaration), procedure & function, type(?)
What about call-by-name?