|
|
CS 334
|
Programming languages provide the interface between the human programmer and the machine. It is the programs that give the machine the ability to do multiple tasks and make them infinitely extensible. To be effective, we must be able to write large, complex, correct, maintainable programs that can be executed on real machines. Programming language design and implementation can have a big impact on these goals.
In 134 and 136 we emphasize object-oriented programming. Classes encapsulate both data and operations. This is the most recent well-accepted trend in programming paradigms. There are other paradigms that have received significant attention over the years:
In this course, we will focus on imperative, object-oriented, and functional languages.
Every programming language provides constructs that allow one to construct programs. The constructs fall roughly into 4 broad categories:
In this course, we will discuss these constructs emphasizing significant variations among languages. In particular, we will focus on how language design choices can affect the expressiveness of a language, the ability to write correct and maintainable programs, and the ability to implement the language.
A programming language must be implementable on real machines. Until recently, efficiency was one of the main concerns. However, as machines become faster, this is becoming less important. Now, it is at least as important for languages to promote the development of correct, maintainable programs. New constructs help the programmer but make the language implementer's job more difficult. There is also increasing emphasis on providing constructs that allow errors to be detected early, at compile-time, rather than late, at runtime (when an unsuspecting user is running the program!). In this course, we will cover both basic implementation topics as well as topics that are particularly relevant for modern languages, including:
This is not a compiler course. (That's 434, which is also offered this term) As a result, we will not discuss mapping programming language constructs to machine language or how to optimize the generated code to maximize efficiency. Instead, the emphasis in this course is on the main abstractions used in these implementations rather than the translation process itself.
When computers were first invented, programs were written in machine language, all 0's and 1's. The first major step upward was assembly language. Assembly language operations generally provide a 1-1 mapping to the operations built in to the computer, so they were just as expressive as machine language. They were somewhat easier to use as the operations had (3-letter) names instead of numbers. Assembly language is rarely used anymore. As recently as 20 years ago, there was still a community of programmers who wanted to use assembly language rather than higher-level languages due to the perception that they could write faster code. This is no longer a viable reason as compiler-generated code can be quite efficient and programmer productivity is immensely greater with higher-level languages.
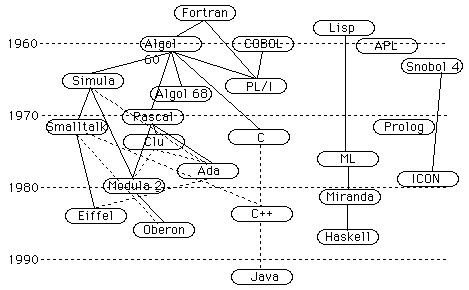
Fortran and Cobol were two of the first imperative programming languages created. Fortran was (and is) primarily used in scientific computations. Its emphasis was on efficient number crunching. Cobol was primarily intended for business processing.
Both of these languages remain popular within their communities. In particular, Fortran has gone through many revisions resulting in a language that works well in highly data-parallel application and is the language of choice for many scientists involved in high performance computing.
Cobol continues to exist largely because there is a large body of legacy code written in it.
Algol 60 was designed shortly after FORTRAN, but never caught on in the U.S., partially because IBM never supported it (think of IBM as the Microsoft of the '60's and '70's in terms of influence on the market). However, it ended up being more influential on later languages. Languages building on it include Algol 68, Pascal, Modula 2, and Ada.
Computer science students are often surprised to hear that Lisp was also a very early programming language, being invented in the early 60s. Lisp is a predecessor of modern functional languages. The emphasis is on symbolic computation and list processing. In addition, it encourages experimentation more than most languages due to its interpreted nature and dynamic type checking. As a result, it was extremely popular among AI researchers for a long time. It has gone through many variations, including object-oriented variations, but its popularity has declined in recent years. These days even AI researchers write large programs and are concerned about efficiency!
Second-generation languages built on the knowledge gained from their predecessors. Interestingly, they took two approaches to this. PL/I (1967) is representative of the "kitchen sink" approach. Take everything from all predecessors and stuff it into a single language. The opposite extreme was taken by Pascal (1971). Here the emphasis was on taking the best ideas and modifying them to work well together. The goal was to create a language that would be good to teach computer programming.
The result may be surprising. The "kitchen sink" approach resulted in a language that was very hard to use and fell into and out of favor relatively quickly. In contrast, Pascal became so popular that it was extended to allow the development of large programs so that it could be used outside of the educational environment.
C also came into existence around this time. Its popularity is probably largely due to the easy transition from assembly language to C. C exposes the underlying machine much more than most programming languages. Thus, for programmers reluctant to give up assembly, it was relatively simple to adopt.
As computers became more prevalent, the demand for programs grew. In addition, the complexity of programs grew. This led to the need to modularize programs, to break them into smaller chunks. Doing this made programs easier to understand (if done well) because it allowed programmers to think about large chunks of their programs abstractly and only worry about details of small parts at a time. Modularization also supported reuse. Common code, such as stacks, trees, etc. could be placed in modules that could be included in multiple programs.
Modula-2 and Ada (both from the early '80s) are probably the most successful languages using modules to define abstract data types, though both were influenced by earlier languages like Clu. In many respects, these are the precursors to today's object-oriented languages, although object-oriented languages can also trace their roots back to Simula (1967) and Smalltalk (1972).
C++ (1986) and Java (1992) both grew out of this community. The growth is fairly analogous to that of PL/I and Pascal. C++ is the kitchen sink. A C++ compiler will accept pure C or you can use the constructs added with C++, like classes, inheritance, templates, etc. Again, its success is due to a very simple transition path from C and due to the fact that there is a lot of legacy code written in C. Moving to C++ allows a gradual transition to object-oriented programming. The result, however, is an extremely complex language with many painful interactions among constructs. Bjarne Stroustroup, the creator of the original version of C++ has this to say about C++:
C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do it blows your whole leg off.
Java took Pascal's approach. Rather than add classes to C, they borrowed C syntax but did not maintain all the constructs of C. Instead, they created a clean and simple object-oriented language with C syntax. (Indeed, it is the plethora of libraries that makes Java complicated to use most effectively!) Probably the main reason that Java has succeeded as much as it has is because it grew up with the Web. By providing applets, Java created a niche. It was not necessary to overtake an existing language with a large legacy base. Indeed, it is the legacy language of the future! As contrast, here is what James Gosling, the inventor of Java has to say about his language:
Java is C++ without the guns, knives and club.
What is in store for future languages? Of course, this is difficult to predict, but one can expect an increased emphasis on constructs that support distributed and mobile computing. We will also likely see a move towards languages that work well in small environments as ubiquitous computing becomes more prevalent.
We will start the "meat" of the course by learning ML, a functional language. The reason to start here is to familiarize you with a radically different programming paradigm. As we discuss constructs and implementation issues later in the semester, the contrast offered by looking across paradigms will be most beneficial. Over the next few classes, we will therefore introduce functional programming in general and ML in particular.
Non-functional languages revolve around the concept of a statement. The purpose of statements is to change the contents of memory (via assignment statements) and use the contents of memory to control computation (via conditionals and loops). Variables are associated with memory locations. When we assign a value to a variable, we are changing the value at that memory location. If multiple variables reference the same memory location, a change to one also changes the other via side effect.
This results in two problems that make it difficult to reason about the behavior of our programs. First, we cannot be certain that 2 calls to a function, passing in the same argument, will return the same value. It is possible that the argument has changed via side effect or that the function depends on the state of some memory other than the function arguments. For example, in C:
int x = 3;
int *y = &x;
printf ("%d\n", succ (x));
*y = 4;
printf ("%d\n", succ (x));The first output produces 4, while the second produces 5. This is pretty obvious here since we can see the creation of the alias and the modification. If these occur via side effect of some method call, this will be much less obvious.
C has another difficulty in that it allows some statements to also be used as expressions. For example, we can say:
x = y = z;
or
x = y++;
Now, what does the following mean?
x = (y++) + (y++);
Is this the same as:
x = 2 * (y++);
Algebraically, it looks as if these should be equivalent. After all x + x = 2 * x. In this case, we cannot make that manipulation, however, because the ++ operator has the side effect of also changing y. In the first case, we increment y twice, while in the second case, we only increment y once.
What about x? Does it get the same value? Well, using the version of C installed on our Unix machines, it is the same. Using Java, it is not. The Java language is very precise about the order of evaluation of expressions. They must be evaluated from left to right. Furthermore, if an expression also results in an assignment (as x++ does), the assignment is done before evaluating the right operand. Thus, the memory associated with y is incremented before y is evaluated as part of the right operand. Thus, x = 2y + 1 (for the original value of y).
In C, x becomes 2y (for the original value of y). The C language specification does not specify in which order the value of y should change relative to the evaluation of the right operand. It is quite possible that different compilers will do this differently!
It is the side effect caused by the ++ operation that makes the example difficult to reason about. We will see, as we look at functional languages, that these side effects cannot happen there.
Back to:
kim@cs.williams.edu