CS 334: HW 5
Instructions
This homework has two types of problems:
-
Self Check: You are strongly encouraged to think about and work through these questions, but you will not submit answers to them.
-
Problems: You will turn in answers to these questions.
Reading
- (Required) Read Mitchell, Chapters 6 and 7.
Problems
1. Type Inference to Detect Race Conditions (Extra Credit)
Note
I've changed this question to be optional extra credit. It's related to some extra material on type inference from last Tuesday -- feel free to work on it if you'd like, but it isn't essential for the rest of the problems.
The general techniques from our type inference algorithm can be used to examine other program properties as well. In this question, we look at a non-standard type inference algorithm to determine whether a concurrent program contains race conditions. Race conditions occur when two threads access the same variable at the same time. Such situations lead to non-deterministic behavior, and these bugs are very difficult to track down since they may not appear every time the program is executed. For example, consider the following program, which has two threads running in parallel:
Thread 1: Thread 2:
t1 := !hits; t2 := !hits;
hits := !t1 + 1; hits := !t2 + 1;
Since the threads are running in parallel, the individual statements of Thread 1 and Thread 2 can be interleaved in many different ways, depending on exactly how quickly each thread is allowed to execute. For example, the two statements from Thread 1 could be executed before the two statements from Thread 2, giving us the following execution trace:
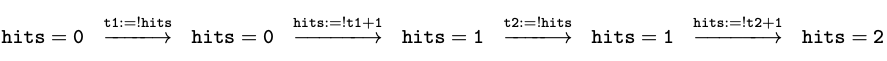
After all four statements execute, the hits
counter is updated from zero to 2, as expected. Another possible
interleaving is the following:
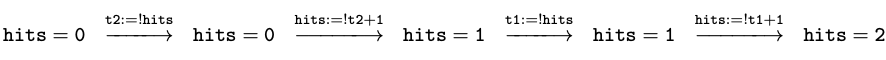
This again adds 2 to hits in the end. However,
look at the following trace:
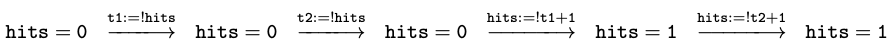
This time, something bad happened. Although both
threads updated hits, the final value is only 1. This is a race
condition: the exact interleaving of statements from the two threads
affected the final result. Clearly, race conditions should be
prevented since it makes ensuring the correctness of programs very
difficult. One way to avoid many race conditions is to protect
shared variables with mutual exclusion locks. A lock is an entity
that can be held by only one thread at a time. If a thread tries to
acquire a lock while another thread is holding it, the thread will
block and wait until the other thread has released the lock. The
blocked thread may acquire it and continue at that point. The
program above can be written to use lock l as follows:
Thread 1: Thread 2:
synchronized(l) { synchronized(l) {
t1 := !hits; t2 := !hits;
hits := !t1 + 1; hits := !t2 + 1;
} }
The statement "sychronized(l) { s }" aquires lock l, executes
s, and then releases lock l. There are only two possible
interleavings for the program now:

and
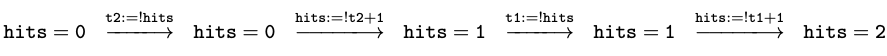
All others are ruled out because only one thread
can hold lock l at a time. Note that while we use assignable
variables inside the synchronized blocks, the names we use for locks
are constant. For example, the name l in the example program above
always refers to the same lock.
Our analysis will check to make sure that locks are used to guard shared variables correctly. In particular, our analysis checks the following property for a program P:
For any variable
yused in P, there exists some locklthat is held by the current thread every timeyis accessed.
In other words, our analysis will verify that every access to a
variable y will occur inside the synchronized statement for some
lock l. Checking this property usually uncovers many race
conditions.
Let's start with a simple program containing only one thread:
Thread 1:
synchronized (m) {
a := 3;
}
For this program, our analysis should infer that lock m protects
variable a.
As with standard type inference, we proceed by labeling nodes in the parse tree, generating constraints, and solving them.
Step 1
Label each node in the parse tree for the program with a variable. This variable represents the set of locks held by the thread every time execution reaches the statement represented by that node of the tree. Note that these variables keep track of sets of locks names, and NOT types, in this analysis.
Here is the labeled parse tree for the example:
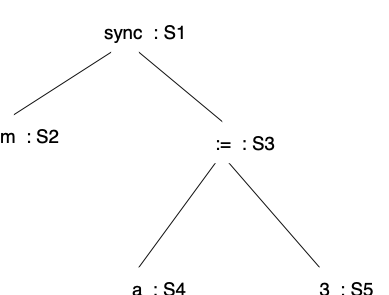
Step 2
Generate the constraints using the following four rules:
-
If S is the variable on the root of the tree, then S = \emptyset.
-
For any subtree matching the form
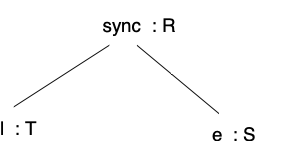
we add two constraints:
\begin{aligned} T & =& R\\ S & = & R \cup \{ {\tt l} \}\end{aligned} -
For any subtree matching the form
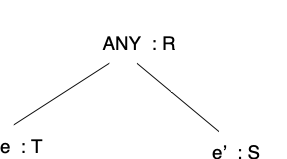
where ANY matches any node other than a
syncnode, we add two constraints:\begin{aligned} T & =& R\\ S & = & R \end{aligned} -
To determine {\tt lock_y}, the lock guarding variable {\tt y}, add the constraint
\begin{aligned} {\tt lock_y} & \in & S\end{aligned}for each node {\tt y}:S or {\tt !y}:S in the tree. In other words, require that {\tt lock_y} be in the set of locks held at each location {\tt y} is accessed.
Here are the constraints generated for the example program:
Step 3
Solve the constraints to determine the set of locks held at each program point and which locks guard the variables:
Clearly,
{\tt lock_a} is m in this case, exactly as we expected.
Questions
You will now explore some aspects of this analysis:
-
Here is another program and corresponding parse tree:
Thread 1: synchronized (l) { synchronized (m) { a := 4; b := !a; } b := 33; }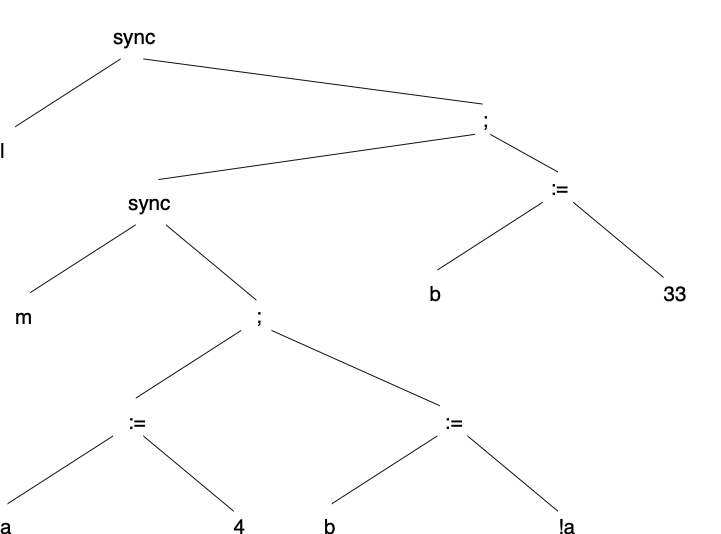
Compute {\tt lock_a} and {\tt lock_b} using the algorithm above. Explain why the result of your algorithm makes sense.
-
Let's go back to the original example, but change Thread 2 to use a different lock:
Thread 1: Thread 2: synchronized(l) { synchronized(m) { t1 := !hits; t2 := !hits; hits := !t1 + 1; hits := !t2 + 1; } }Compute {\tt lock_{t1}}, {\tt lock_{t2}}, and {\tt lock_{hits}} using the algorithm above. Since there are two threads in the program, you should create two parse trees, one for each thread. Explain the result of your algorithm.
-
Suppose that we allow assignments to lock variables. For example, in the following program,
landmare references to locks, and we can change the locks to which those names refer with an assignment statement:Thread 1: Thread 2: synchronized(!l) { synchronized(!m) { a := !a + 1; x := !b + 3 } b := 11 + x; m := !l; } synchronized(!m) { a := !b + 1; b := !a; }Describe any problems that arise due to assignments to lock variables, and what the implications for the analysis are. You do not have to show the constraints from this example or change the analysis to handle mutable lock variables. A coherent discussion of the issues is sufficient. Thinking about what the algorithm would compute for {\tt lock_a}, {\tt lock_b}, and {\tt lock_x} may be useful, however.
2. Parameter Passing (10 pts)
Mitchell, Problem 7.4
3. Swift Parameter Modes (20 pts)
This question explores parameter modes in the context of Apple's Swift language. We'll look at three modes: in, in-out, and out. Here is an example of each in Swift:
func test1(x: Int) -> Int { ... } /* default is "in" mode */
func test2(x: inout Int) -> Int { ... } /* "inout" mode */
func test3(x: out Int) -> Int { ... } /* "out" mode */
(Swift doesn't actually support the "out" mode, but other languages do, most notably Ada.) The three modes, have the following meaning:
- in: The value of the parameter x cannot be changed inside the function. If we call
test1(y), the value of y is the same before and after the call. - inout: The parameter x can be both read and written, and the value of y after a call to
test2(&y)is the last value written to x in the function. The&in the call to text2 is required by Swift to indicate that y is being passed as an in-out parameter. - out: The parameter x can be written to, but it cannot be read. If we call
test3(&y), the value of y after the call is the last value written to x in the function.
Questions
-
Why do you think the designers of Swift require the "
&" for in-out and out parameters at call sites? -
The language definition does not fully specify how each mode must be implemented, and the compiler may use any appropriate parameter passing mechanism to implement them.
Which parameter passing mechanism could be used to implement
test1,test2, andtest3? The choices are "pass-by-reference", "pass-by-value", and "pass-by-value-result" (as described in Problem 7.6). If more than one is possible, describe the advantages/disadvantages of each. -
In general, what is the advantage of permitting the compiler flexibility in how it implements parameter modes for such functions?
-
Now consider the following function that takes two parameters. Would the function
mainprint the same value for all strategies you outlined fortest2above? If it doesn't, why might that be problematic?func incTwo(a: inout Int, b: inout Int) { a += 1; b += 1; } func main() { var w : Int = 3; incTwo(&w, &w); print(w); } -
Swift disallows passing the same variable as two different in-out parameters, meaning the call to
incTwo(&w, &w)would be an error. Is this sufficient to avoid any problematic behavior identified in the previous part? There are alternative ways to achieve the same effect. Identify at least one. Why did you think the designers of Swift choose the option they did?
4. Static and Dynamic Scope (10 pts)
Mitchell, Problem 7.8
5. Function Returns and Memory Management (15 pts)
We still have some material to cover for this one, so you may wish to hold off until next Tuesday for this one.
Mitchell, Problem 7.13
Note: g in the diagram in the book is a pointer and should have a dot next to it like the other pointers.
Submitting Your Work
Submit your answers to the GradeScope assignment named, for example, "HW 0". It should:
- be clearly written or typed,
- include your name and HW number at the top,
- list any students with whom you discussed the problems, and
- be a single PDF file, with one problem per page.
You will be asked to resubmit homework not satisfying these requirements. Please select the pages for each question when you submit.